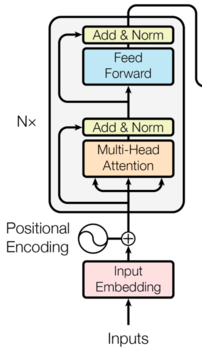
Encoder in Transformer
Machine Learning
Deep Learning
Paper Implementation
NLP
Transformer
This is a brief overview of the Encoder in the Transformer architecture based on my understanding.
- In general in the architecture there is an Encoder and Decoder.
- Encoder has n = 6 identical layers.
- Each encoder layer has 2 sub-layers. First sub-layer is for Multi-Head Attention and the Second sub-layer is for feed-forward neural network.
- And for each sub-layer has a layerNorm on top of it along with a skip connection as well.
- The output of each sub-layer is like LayerNorm(\(x +\) Sublayer(\(x\)))
- The advantage of LayerNorm is
- helps reduced internal covariate shift, leads to faster training.
- it normalizes the inputs across features (last dimension), and not across the batch.
- not advantage: it has some learnable parameters \(a\) and \(b\) where they are for scaling and bias respectively.
- The output of layerNorm \(\rightarrow\) \(a*x_{norm} + b\)
- So like this Encoder Block \(\rightarrow\) [ \(E_1\), \(E_2\), \(E_3\), \(E_4\), \(E_5\), \(E_6\)]
- Each \(E_i\) has [ Sub-Layer 1, Sub-Layer 2]
- where Sub-Layer 1 is Self Attention (or Multi-Head Attention)
- and, Sub-Layer 2 is Feed Forward Neural Network
- Also, x \(\rightarrow\) Sub-Layer \(i\) results in LayerNorm(\(x +\) Sublayer_i(\(x\)))
References: - https://jalammar.github.io/illustrated-transformer/ - https://nlp.seas.harvard.edu/annotated-transformer/ - Attention is All You Need